
今天要分享的是網路爬蟲(Web Crawler)的基本概念與PTT爬蟲實作!
#使用的網頁是PTT的NBA版
首先是網路爬蟲(Web Crawler)的基本概念:
網際網路的資料傳遞是網狀分布,網路爬蟲的代表圖示是蜘蛛,為了獲取資料而在網路中爬行尋找並收集所需的資訊,即為網路爬蟲。
原始碼:當造訪PTT的NBA版網址時,伺服器會回傳要顯示的網頁(格式為HTML),而此HTML檔案就是網頁的原始碼
#使用Python跟Request函式庫來取得HTML進行資料分析
反爬蟲:伺服器阻止爬蟲爬取資料的手段,常見的方式如檢查請求的Header、輸入驗證碼、滑動解鎖(驗證是否為人類)
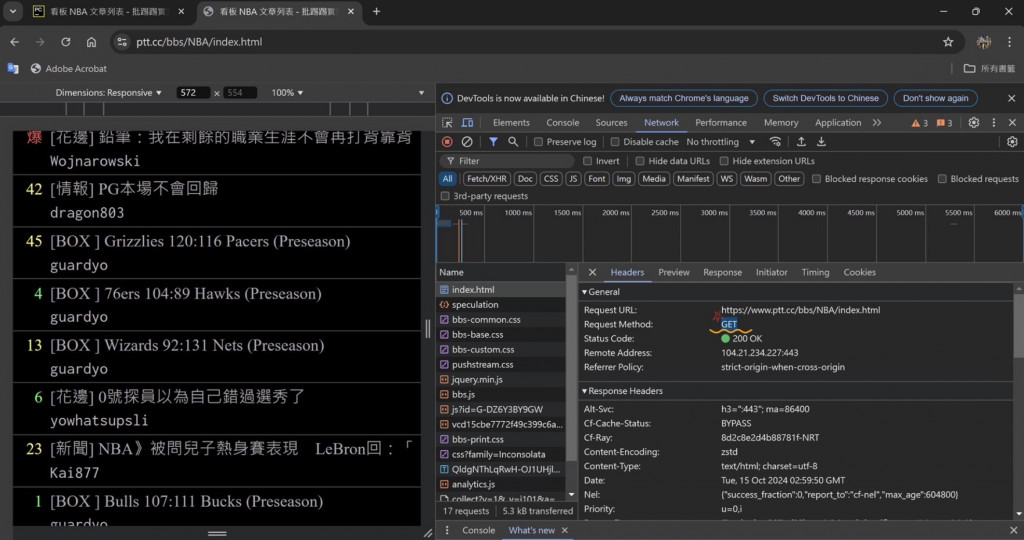
#要模仿使用者發出的請求Header的話,需先使用瀏覽器觀察使用者發出的請求(Request)
接下來是PTT爬蟲實作:
#爬蟲主要流程:
決定從網頁中爬取哪些資料=>分析網頁原始碼/提取資料=>用Python撰寫爬蟲,此步驟分為下載網頁(Requests)與分析網頁(BeautifulSoup)=>儲存成結構化格式
一般的網頁會去檢查你的User Agent是否為真人,如果是機器人、爬蟲的話就會被阻擋,所以加入User Agent模仿使用者是一種常見的爬蟲技巧
#截圖中包含詳細的手寫註解供參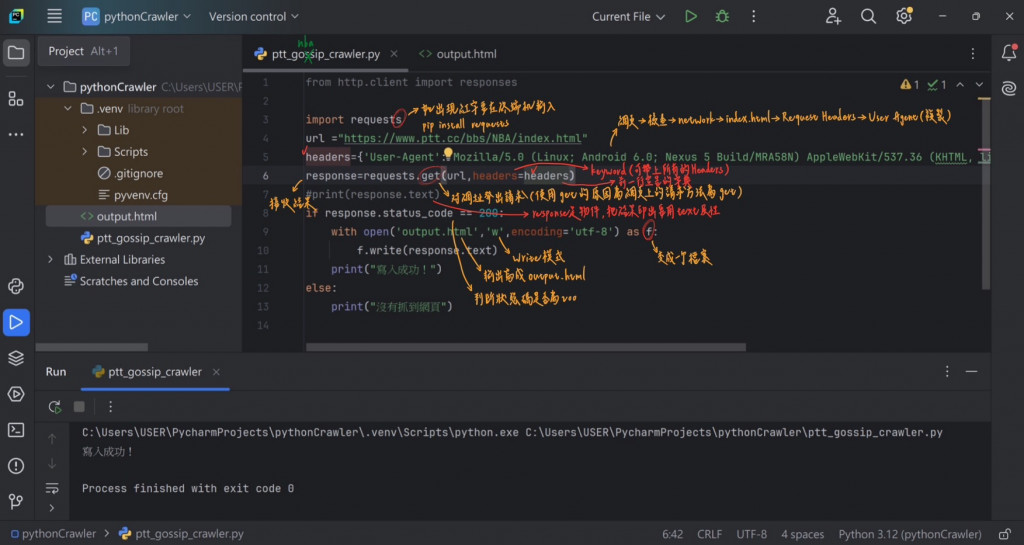
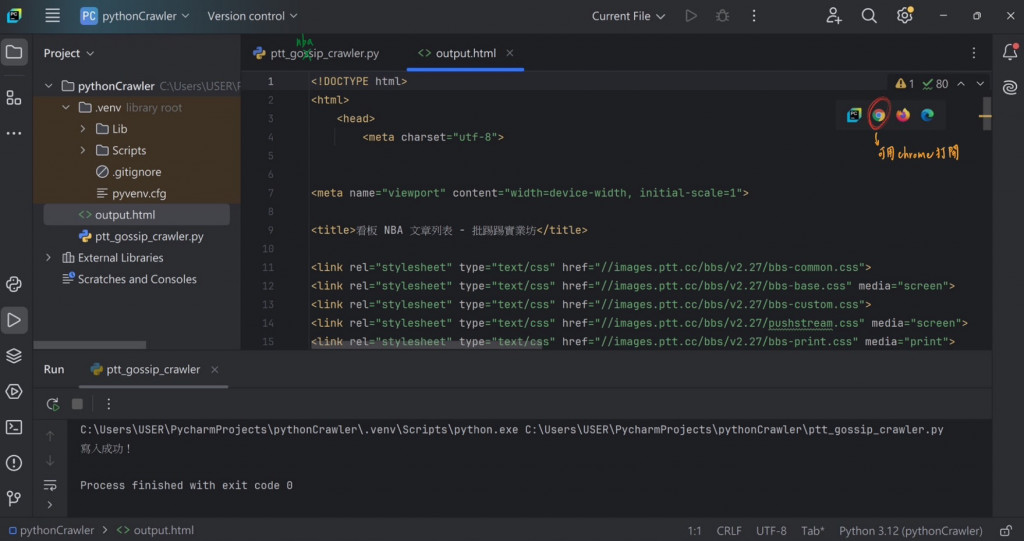
存成JSON格式,程式碼如下
JSON格式:通常用在前後端API的交換,想獲取其他伺服器的資料或想把資料提供給別人時可使用此格式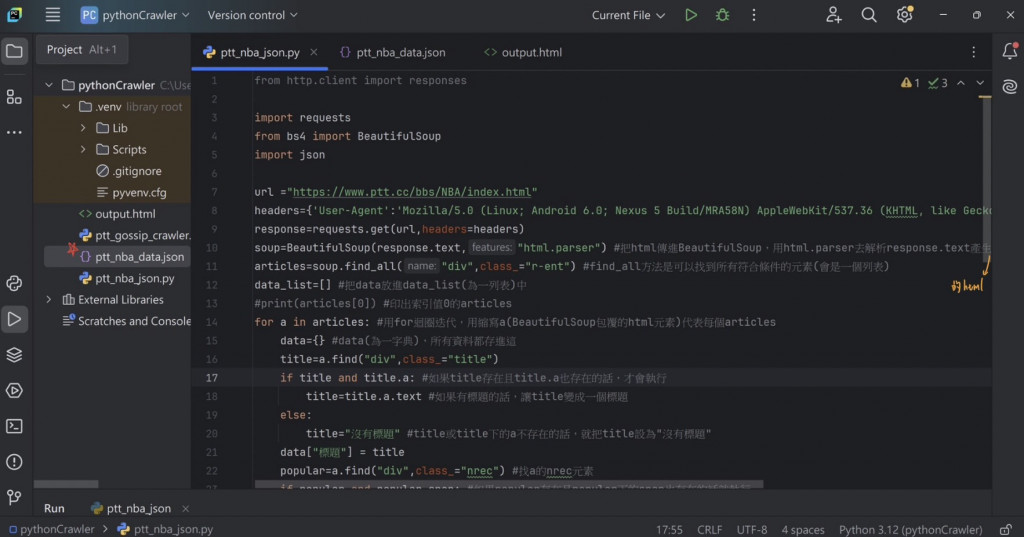
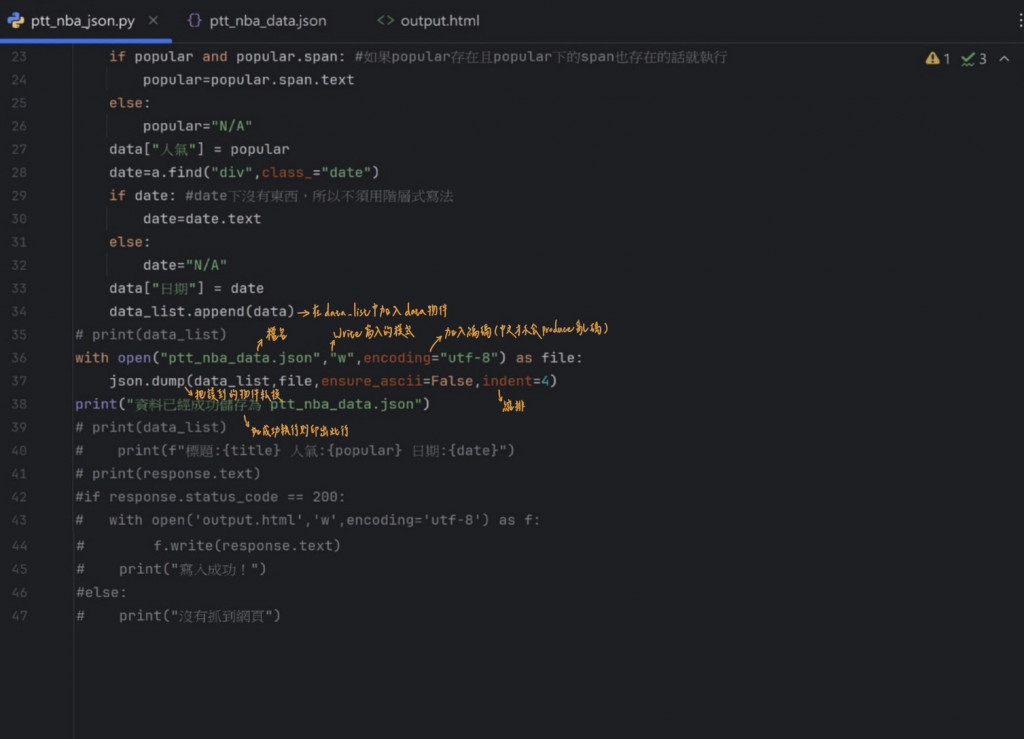
執行結果為(在pythonCrawler中會出現ptt_nba_data.json檔案):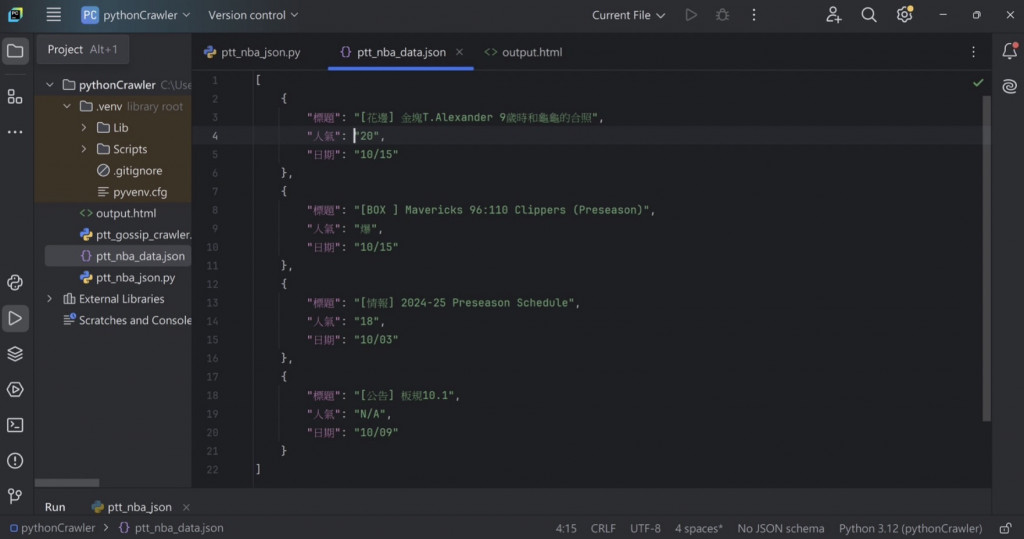
如果執行成功,會顯示此行: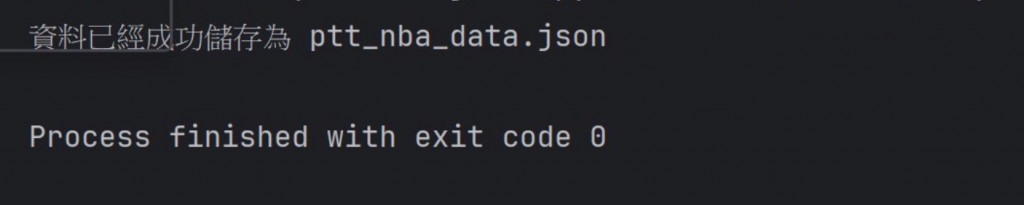
存成Excel格式,程式碼如下(大致上跟JSON相似,只有標出的地方需要修改)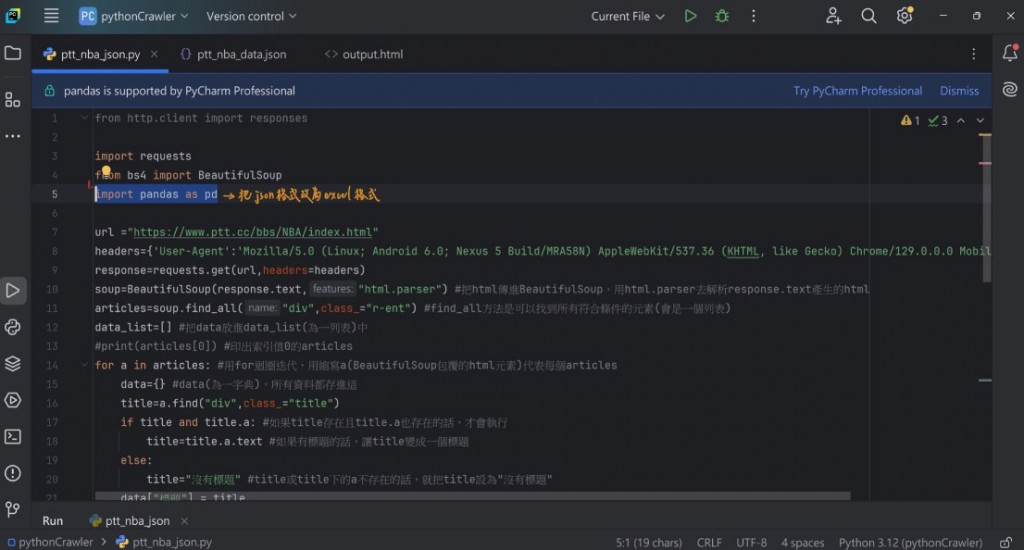
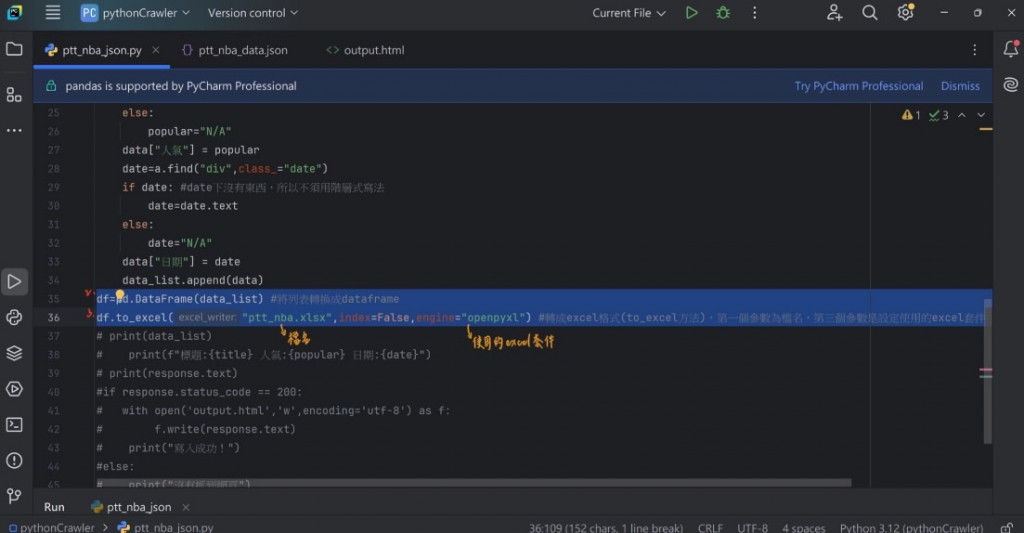
執行結果為(在pythonCrawler中會出現ptt_nba.xlsx檔案,點擊後便會跑出此頁面):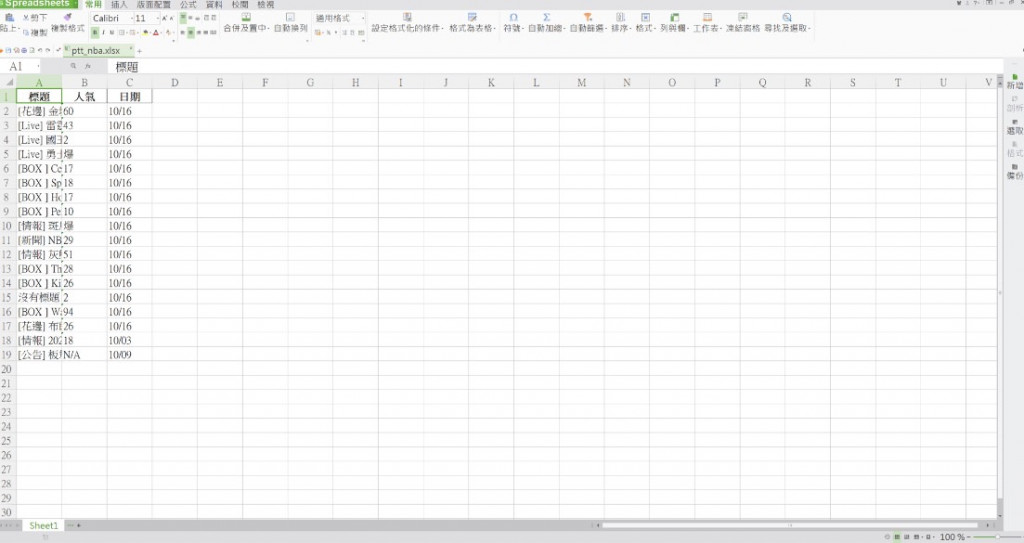
以上是我今天的分享,謝謝大家!
參考網址:https://www.youtube.com/watch?v=1PHp1prsxIM&list=LL&index=5

 iThome鐵人賽
iThome鐵人賽